Console
install.packages("pak")In order to participate in this course, you must complete everything in this pre-course tasks section and finish with completing the survey at the end. These tasks are designed to make it easier for everyone to start the course with everything set up. For some of the tasks, you might not understand why you need to do them, but you will likely understand why once the course begins.
Depending on your skills and knowledge, these tasks could take between 3-5 hrs to finish, so we suggest planning a full day to complete them. Depending on your institution and how they handle installing software on work computers, you also might have to contact IT very early to make sure everything is properly installed and setup.
Here’s the list of tasks you need to do. Specific details about them are found as you work through the tasks.
Check each section for exact details on completing these tasks.
In general, these pre-course tasks are meant to help prepare you for the course and make sure everything is setup properly so the first session runs smoothly. However, some of these tasks are meant for learning as well as for general setup, so we have defined the following learning objectives for this page:
We will explain this a bit during the course, but read this to start learning how the website is structured and how to read certain things. Specifically, there are a few “syntax” type formatting of the text in this website to be aware of:
/, for example data/ means the data folder.x <- 10, x is a variable because it was assigned with 10.(), for instance mean() or read_csv().:: to indicate to run the code from the specific package, since we likely haven’t loaded the package with library(). For instance, to install packages from GitHub using the pak package we use pak::pkg_install("user/packagename"). You’ll learn about this more later.The first thing to do is to install these programs. You may already have some of them installed and if you do, please make sure that they are at least the minimum versions listed below. If not, you will need to update them.
R.version.string in the Console.Help -> About RStudio.R: Any version above 4.4.0. If you have used R before, you can confirm the version by running R.version.string in the Console. If you use Homebrew, installing R is as easy as opening a Terminal and running:
brew install --cask rRStudio: Any version above v2024.09.1+394. If you have installed it before, check the current version by going to the menu Help -> About RStudio. With Homebrew:
brew install --cask rstudioGit: Git is used throughout many sessions in the courses. With Homebrew:
brew install gitR: Any version above 4.4.0. If you have used R before, you can confirm the version by running R.version.string in the Console.
sudo apt -y install r-baseRStudio: Any version above v2024.09.1+394. If you have installed it before, check the current version by going to the menu Help -> About RStudio.
Git: Git is used throughout many sessions in the courses.
sudo apt install gitAll these programs are required for the course, even Git. Git, which is a software program to formally manage versions of files, is used because of it’s popularity and the amount of documentation available for it. Check out the online book Happy Git with R, especially the “Why Git” section, for an understanding on why we are teaching Git. Windows users tend to have more trouble with installing Git than macOS or Linux users. See the section on Installing Git for Windows for help.
Some pictures may show a Git pane in RStudio, but you may not see it. If you haven’t created or opened an RStudio R Project (which is taught in the introductory course), the Git pane does not show up. It only shows up in R Projects that use Git to track file changes.
A note to those who have or use work laptops with restrictive administrative privileges: You may encounter problems installing software due to administrative reasons (e.g. you don’t have permission to install things). Even if you have issues installing or updating the latest version of R or RStudio, you will likely be able to continue with the course as long as you have the minimum version listed above for R and for RStudio. If you have versions of R and RStudio that are older than that, you may need to ask your IT department to update your software if you can’t do this yourself. Unfortunately, Git is not a commonly used software for some organizations, so you may not have it installed and you will need to ask IT to install it. We require it for the course, so please make sure to give IT enough time to be able to install it for you prior to the course.
Once R, RStudio, and Git have been installed, open RStudio. If you encounter any troubles during these pre-course tasks, try as best as you can to complete the task and then let us know about the issues in the pre-course survey of the course. If you continue having problems, indicate on the survey that you need help and we can try to book a quick video call to fix the problem. Otherwise, you can come to the course 15-20 minutes earlier to get help.
If you’re unable to complete the setup procedure due to unfixable technical issues, you can use Posit Cloud (to use RStudio on the cloud) as a final solution in order to participate in the course. For help setting up Posit Cloud for this course, refer to the Posit Cloud setup guide.
During this course, we will be spending most of our time in RStudio. RStudio is an “environment” that we use to interact with R. R is like an engine, while RStudio is like the tools we use to actually work with that engine. Prior to taking a look at what RStudio looks like, let’s talk briefly about R as a programming language.
R is a free programming language/environment used in statistical computing, data analytics, and scientific research. R is used to clean, organize, analyze, and report on data. R has powerful visualization features, so it is a particularly useful tool for creating charts and figures. R is different from SPSS and other statistical programs in that you run analyses by typing commands in a console rather than using click-based, drop-down menus.
In recent years, R has become one of the most popular languages among statisticians and data scientists for several reasons:
However, like many programming languages, R is not easy to learn. Some functions are spread across packages, which means that you need to have prior knowledge of packages in order to implement some commands. R can also be slower than other programming languages. Nonetheless, R offers such a supportive community and rich functionality that it is worth the challenge!
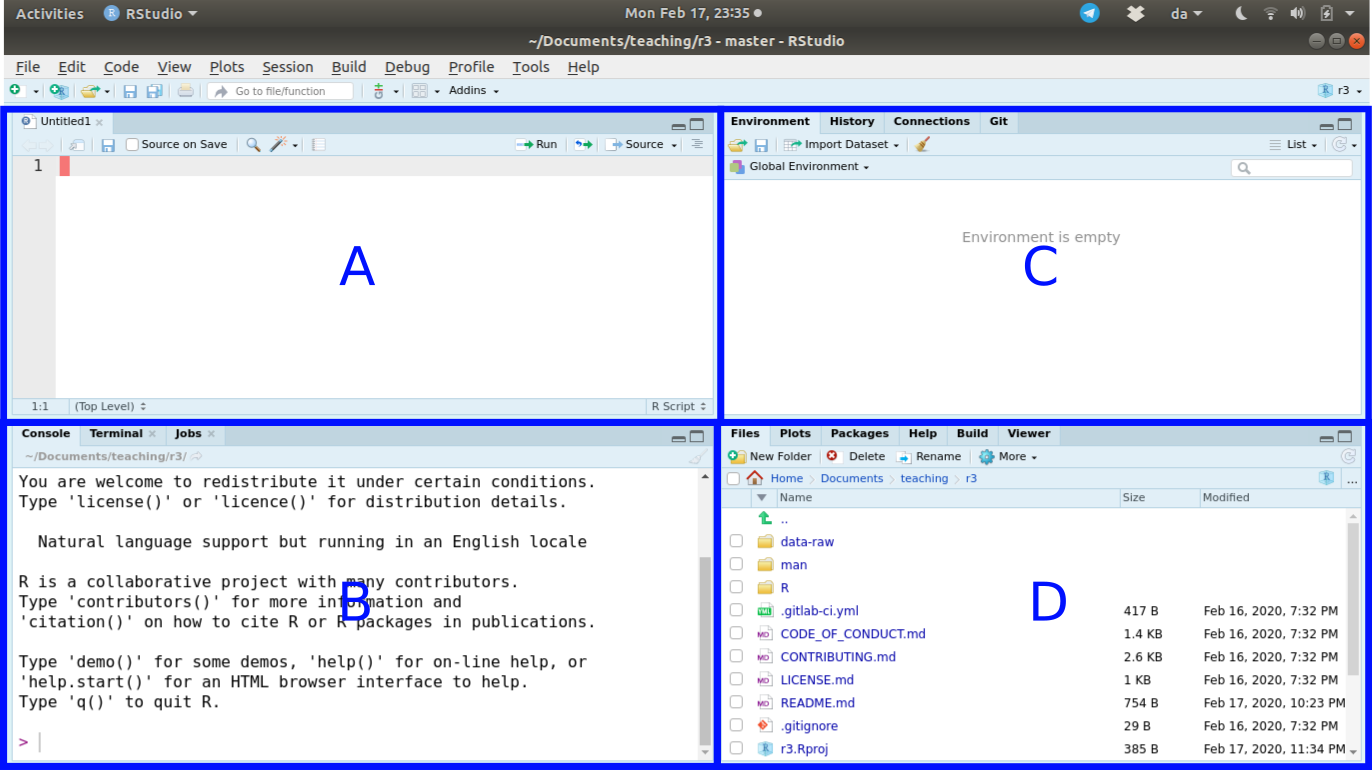
Let’s start learning about RStudio and how to use it. Check out Figure 3.1 below. You can see that RStudio has four “panels”, dividing the screen into the four sections.
This image, along with the other images and videos below, may look slightly different from your own computer depending on your operating system and other settings.
While you can customize where the individual panels go, the default layout is how the panels are shown.
While we will spend part of the course using an R script to play around with code, we will also be learning and using R Markdown / Quarto (.Rmd or .qmd files). R Markdown / Quarto is a dynamic and invaluable tool that will help make your analysis more reproducible. Quarto is an upgraded version of R Markdown but can also use R Markdown. Throughout the rest of the course, we will write and talk about Quarto, but we mean both Quarto and R Markdown. We will explain this in more detail in Chapter 6.
Quarto allows you to interweave chunks of code along with text and images. R runs the code and inserts the code output into the Quarto file. The Quarto document can be converted into a wide range of document types, including MS Word, PDF, or HTML. Some researchers write and manage entire papers, theses, websites, or books using Quarto, as it can make things easier to organize and maintain. In fact, this website is written with Quarto.
Now that you have RStudio and R on your computer, we need to install the R packages we’ll use in the course. R packages are bundles of R code that other people have written. There are so many R packages available that there is likely an R package for anything you’d like to do in R. Making use of R packages can greatly help you out when doing your research.
Before we continue, we need to briefly explain what some terms mean.
mean() is a complete piece of text that tells R to calculate the mean of some numbers.
() at the end (at least in this course), that means it is a function.mean() above..R that contains R code that completes tasks in a sequence (from the top of the file to the bottom).For this course, we will be focusing on R packages that are powerful and general-purpose enough to help you in multiple aspects of your research. To install these packages, we’ll need to install the r3 helper package. For that, we’ll need to first install the pak package. Watch the video (no audio) below to see how to do this:
Or paste the following code into the RStudio R Console:
Console
install.packages("pak")Copy and paste the function below into the RStudio Console. Hit Enter and the r3 helper package will be installed. Watch the video below to see how to do this. Note, what you see in the video (no audio) may look different from yours.
Console
pak::pkg_install("rostools/r3", upgrade = TRUE)You might encounter an error when running this code. That’s ok, if you restart R by going to Sessions -> Restart R and re-running this code, it should work. If it still doesn’t, try to complete the other tasks, complete the survey, and let us know you have a problem in the survey.
It is important to understand what you are doing when you enter a function like something::something(). In the example of pak::pkg_install(), you would “read” this as:
R, can you please use the
pkg_installfunction from the pak package?
You could load the package with library(pak) and then run the pkg_install() function. However, using the :: (pronounced “colon colon”) tells R that we want to use a function directly from a package. We prefer this way as we only want to use the pkg_install() function from the pak package without having to load all the other functions. We will be using :: often during this course.
Most of the packages we will be using in this course are bundled together into one package called tidyverse. This package is a collection of packages that are designed for common tasks in data science, ranging from data exploration to data visualization. As the name suggests, tidyverse is an attempt to organize the “universe” of data analysis by providing packages that guide workflows and lead to more reproducible analysis projects. To install all the packages we will use for this course, copy and paste this command into the R Console:
Console
Like with the installing of r3 in the video above, this will take some time to install everything. Normally, to install packages, you would type this in the Console (you don’t need to do this):
Console
install.packages("tidyverse")The specific packages from tidyverse that we will use are ggplot2 and dplyr. These packages provide a set of tools for the most common data analysis tasks and have excellent documentation and tutorials on how to use them.
dplyr (along with a complementary package tidyr) is a package that is very popular and contains important data manipulation functions, including functions that select and/or create variables depending on certain conditions. dplyr is built to work directly with data frames (rectangular data like those found in spreadsheets), and has an additional feature to interact directly with data stored in an external database such as in SQL. Working with databases is a powerful way to work with massive datasets (100s of GB), more than what your computer could normally handle. Working with massive data won’t be covered in this course, but see this resource from Data Carpentry to learn more.
ggplot2 is a data visualization package that can be used to create bar charts, pie charts, histograms, scatterplots, error charts, and more. It uses a “grammar” as a way to construct and customize your graphs in a layered, descriptive approach.
We’ll cover more about Git and GitHub during the course, but for now, please read Section 7.2, Section 7.3, and Section 7.4. During the course you will read them again and we will verbally explain it in more detail. Why repeat this twice? Because Git and version control are some of the more difficult things you will learn in this course and because they are fundamentally very different ways of working in your computer than you are probably used to. They require changing how you see and interact with your projects and computer in pretty big ways. So we want you to read this now so you can start to mentally process the concepts we will cover. Then we’ll get you to read it again during the course, to reinforce the concepts.
After reading about Git, we need you to prepare things so that you are ready for the course. In order to use Git properly, you need to inform your computer that you are using Git. The r3 course helper package has a function to help with this. Type in the RStudio Console:
Console
r3::setup_git_config()Hit enter and follow the instructions. Finally, type and run this next function to make sure everything is working with your setup. When you complete the survey later, you will need to copy and paste the output of this function.
Console
r3::check_setup()If everything is fine, you will see something that looks like:
Checking R version:
✔ Your R is at the latest version of 4.4.2!
Checking RStudio version:
✔ Your RStudio is at the latest version of 2024.9.0.375!
Checking Git config settings:
✔ Your Git configuration is all setup!
Git now knows that:
- Your name is 'Luke W. Johnston'
- Your email is 'lwjohnst@gmail.com'After you are done, you need to create a GitHub account. Make note of your username, as we will ask you for it in the pre-course survey. Make sure to remember your password, either write it down somewhere or (even better) use a password manager to store your password for you.
GitHub is a company and website, while Git is a software. There is sometimes confusion about these two things since they both say “Git”. It’s important to distinguish that they are two separate things.
Most of the description of the course is found in the syllabus (Chapter 1). While you may have signed up to this course to learn more about R, you should know that conducting reproducible research goes beyond R and RStudio. As such, we will be spending a lot of time exploring other tools that are used in conjunction with R, to improve the structure and transparency of your work. This course is designed to not only introduce you to R, but also to show ways of conducting reproducible research and data analysis in R.
If you haven’t read the syllabus, please read it now. Read over what the course will cover, what we expect you to learn by the end of it, and what our basic assumptions are about who you are and what you already know. At the end of this section, we’ll ask you a few questions to see if you understand what you’ll learn in the course.
One goal of the course is to teach about open science, and true to our mission, we practice what we preach. The course material is publicly accessible (all on this website) and openly licensed so you can (re-)use it for free! The material is organized in the order that we will cover it in the course.
While the course will include lots of hands-on work during the sessions, the final group project assignment (Chapter 14) will allow you to practice everything you’ve learned in a team setting. Please read it to get familiar with what is expected of you.
We have a Code of Conduct. If you haven’t read it, read it now. The survey involves a question about Conduct. We want to make sure this course is a supportive and safe environment for learning, so this Code of Conduct is quite important.
Throughout the many times we’ve taught this and other workshops we get asked a lot of questions. We have a Frequently Asked Questions page for keeping track of some of these questions. Check out this page, maybe your question has already been answered!
If you want to get help virtually or after the workshop, you can join the Discord channel where you can ask questions in the questions-or-advice text channel.
You’re almost done. Please fill out the pre-course survey to finish this section, either at this link.
See you at the course!